Scaling Beyond the Monolith
As applications grow in users, features, and traffic, architectural decisions that worked at small scale can become serious bottlenecks. In this section, we'll explore the limitations of our current single-database architecture and introduce new technologies to build a truly scalable, cloud-native system.
The Challenge of Scale
Our current architecture uses a single PostgreSQL database for all application data. This approach is simple and works well for getting started, but as systems mature, several challenges emerge:
Performance Bottlenecks
When handling hundreds to thousands of requests per minute, a single database becomes a critical bottleneck:
- Connection pool exhaustion: Limited database connections must be shared across all operations
- Query contention: Different workloads (reads vs. writes, simple vs. complex queries) compete for resources
- I/O limitations: Storage throughput becomes constrained under heavy load
- CPU saturation: Complex queries and high transaction volumes max out database compute
Cost Implications
Scaling a single database vertically (adding more CPU, RAM, and storage) quickly becomes expensive. Enterprises often find themselves spending thousands of dollars monthly on oversized database instances that still struggle to meet demand. The cost-to-performance ratio degrades rapidly as you scale up.
Lack of Specialization
Different types of data have different access patterns and requirements:
- Transactional data (orders, enrollments) needs strong consistency and ACID guarantees
- Shopping cart data needs high throughput and low latency, but can tolerate eventual consistency
- Cache data needs extremely fast access but can be volatile
- Background jobs need asynchronous processing without blocking user requests
Using one database for all these workloads means we can't optimize for any of them.
Current Architecture
Let's visualize our current system architecture:
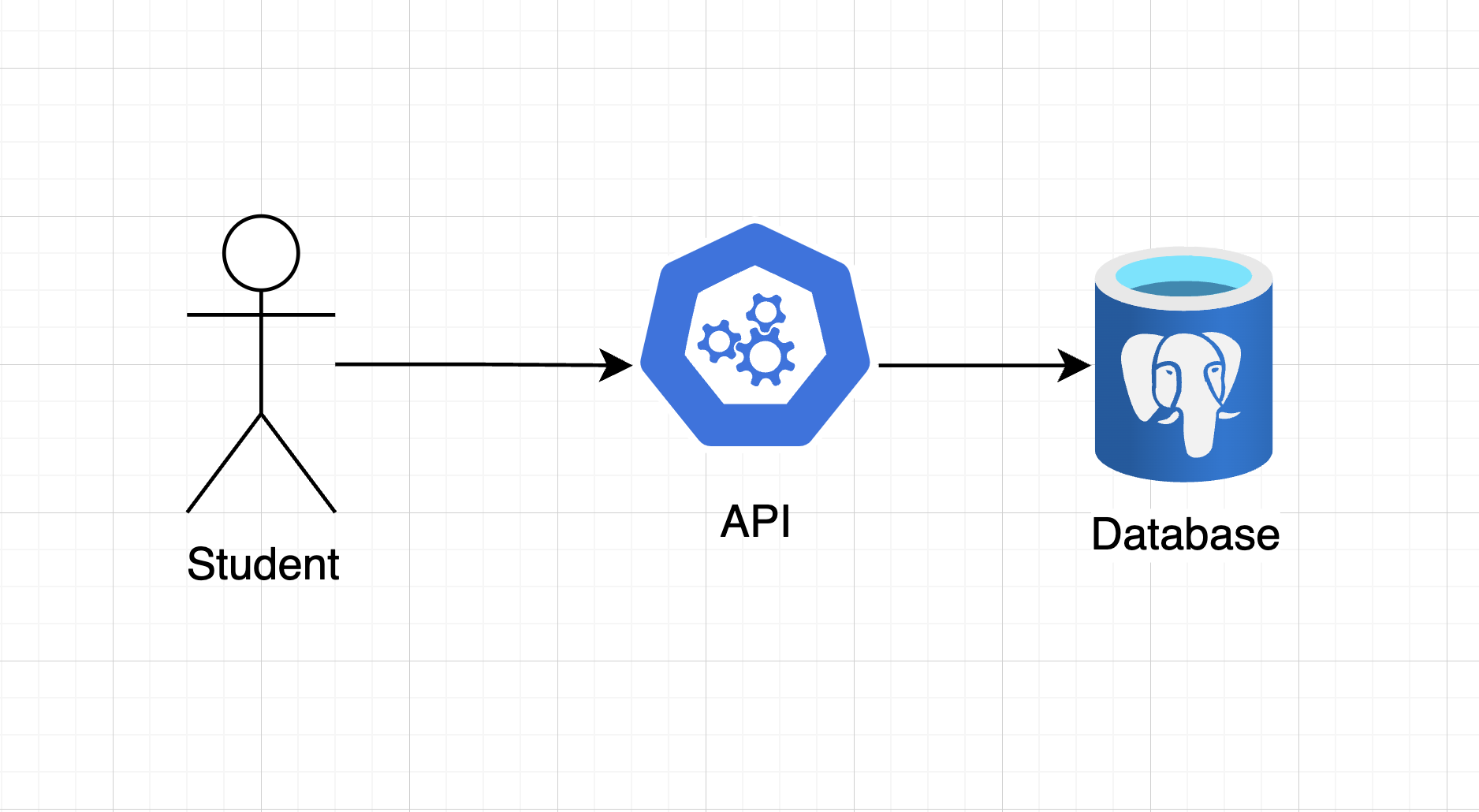
As you can see, all application logic flows through our API to a single PostgreSQL database. This simple architecture has served us well during development, but it's time to evolve.
Evolution Strategy
To build a scalable, cloud-native distributed system, we'll introduce three foundational technologies that address specific scaling challenges. Each technology serves a distinct purpose and solves real problems.
1. NoSQL Document Database: Azure Cosmos DB
Purpose: Horizontally scalable storage for high-throughput, low-latency data access.
Why NoSQL?
Traditional relational databases like PostgreSQL are optimized for:
- Strong consistency (ACID transactions)
- Complex relationships and joins
- Flexible querying with SQL
NoSQL databases like Cosmos DB are optimized for:
- Massive scale (millions of operations per second)
- Global distribution
- Predictable low latency
- Flexible schema evolution
The Tradeoff
NoSQL databases achieve incredible scale by relaxing certain guarantees:
- Eventual consistency: Updates propagate asynchronously across replicas
- Limited joins: Data must be denormalized for efficient access
- Partition key design: You must choose a partition strategy upfront
These tradeoffs are acceptable (even preferable) for certain workloads like shopping carts, user sessions, or activity feeds.
Our Use Case
We'll migrate our shopping cart functionality to Cosmos DB because:
- Cart operations are high-frequency (students add/remove items constantly)
- Cart data is independent (no complex joins needed)
- Low latency is critical for good user experience
- Cart data is temporary and doesn't need strong consistency guarantees
2. Distributed Cache: Redis
Purpose: Ultra-fast in-memory data store for frequently accessed data.
Why Distributed Caching?
In a horizontally scaled application, in-memory caching creates problems:
- Each instance has its own cache
- Cache invalidation becomes complex
- Memory is wasted with duplicate data
- Inconsistent data across instances
A distributed cache like Redis solves these issues by providing a single, shared cache accessible by all application instances.
Redis Benefits
- Speed: Sub-millisecond latency for most operations
- Data structures: Not just key-value; supports lists, sets, sorted sets, and more
- Persistence options: Can be configured for durability or pure speed
- Proven reliability: Battle-tested in production at massive scale (Twitter, GitHub, Stack Overflow)
Our Use Case
We'll use Redis to cache:
- Course catalog data: Course details rarely change but are read frequently
- Shopping cart data: Add a caching layer in front of Cosmos DB
- Session data: User authentication tokens and preferences
This reduces database load and improves response times dramatically.
3. Asynchronous Messaging: RabbitMQ
Purpose: Decouple services and enable asynchronous, event-driven workflows.
Why Asynchronous Messaging?
Not every operation needs to complete during the HTTP request/response cycle. Many tasks can (and should) happen asynchronously:
- Email notifications: Students don't need to wait for confirmation emails
- Order processing: Enrollment can happen after payment completes
- Analytics: Usage tracking can be processed in the background
- Data synchronization: Cross-service data updates can be eventual
Message brokers enable this by decoupling producers (services that emit events) from consumers (services that process events).
RabbitMQ Benefits
- Reliability: Messages are persisted and guaranteed delivery
- Flexible routing: Powerful routing capabilities with exchanges and queues
- Standard protocol: Uses AMQP, an open standard
- Battle-tested: Millions of messages per second in production systems
Our Use Case
We'll use RabbitMQ for:
- Order processing: When a student purchases courses, publish an "OrderPlaced" event
- Enrollment: A background worker consumes the event and enrolls the student
- Resilience: If enrollment fails, the message can be retried automatically
This makes our checkout flow faster (payment completes immediately) and more resilient (enrollment retries on failure).
Target Architecture
By the end of this section, our system will evolve to look like this:
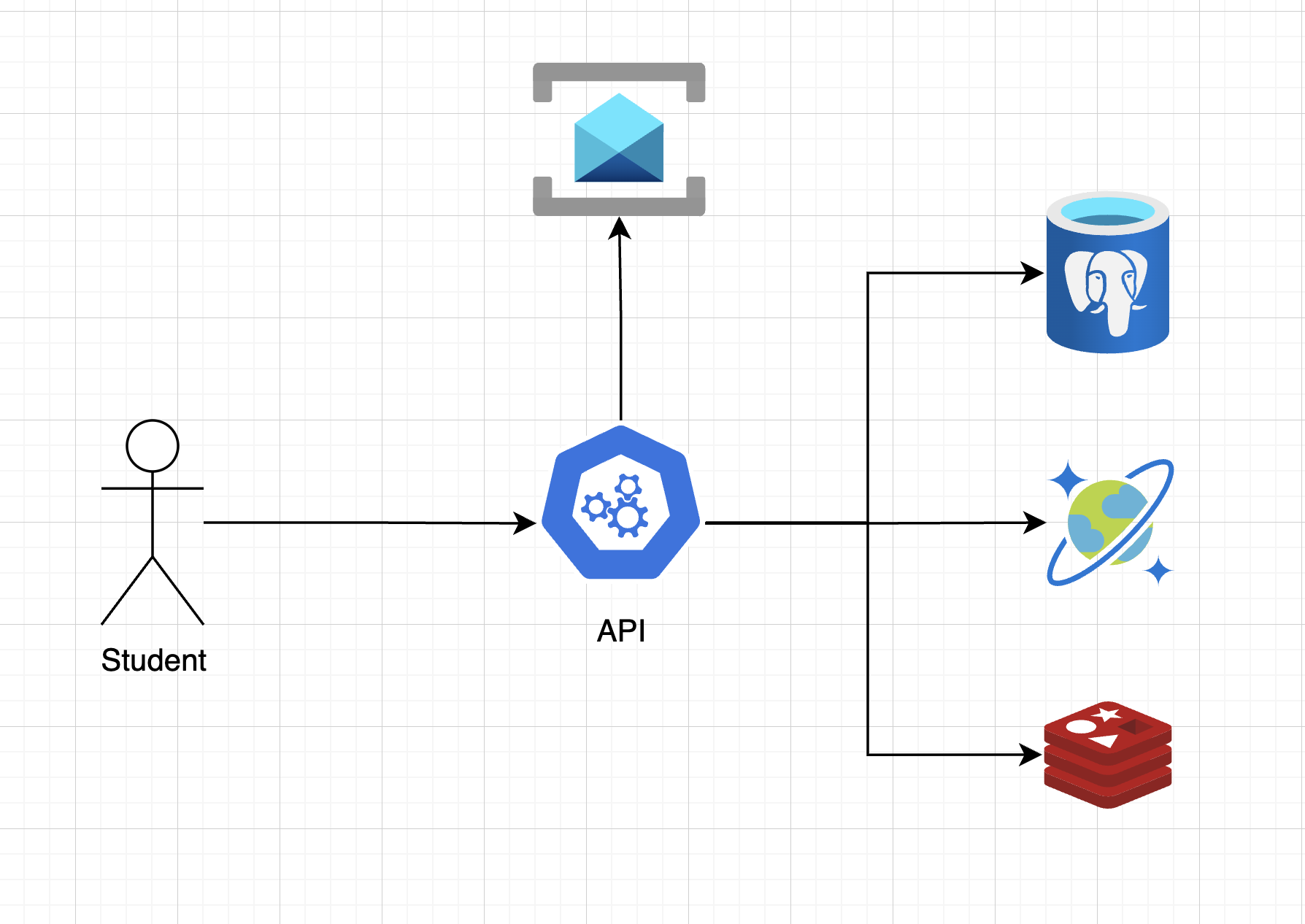
Notice how we've:
- Separated concerns: Different databases for different workloads
- Added caching: Redis sits between our application and databases
- Enabled async processing: RabbitMQ handles background jobs
- Maintained simplicity: The API still provides a unified interface
What We'll Build
In the following sections, we'll implement this architecture step by step:
- Azure Setup: Configure Azure credentials and subscriptions
- Shopping Cart Migration: Move cart data to Cosmos DB
- Redis Caching: Implement distributed caching for course and cart data
- Asynchronous Messaging: Replace synchronous enrollment with event-driven processing
Each step will demonstrate a key cloud-native pattern while improving our system's scalability, performance, and resilience.
Let's begin!